Introduction
Recently, I stepped into the AWS ecosystem to learn and explore its capabilities. I’m documenting my experiences in these series of posts. Hopefully, they will serve as a reference point to me in future or for anyone else following this path. The objective of this post is, to understand how to create a data pipeline. Read on to see how I did it. Certainly, there can be much more efficient ways, and I hope to find them too. If you know such better method’s, please suggest them in the comments section.
How to upload external data in Amazon AWS S3
Step 1: In the AWS S3 user management console, click on your bucket name.
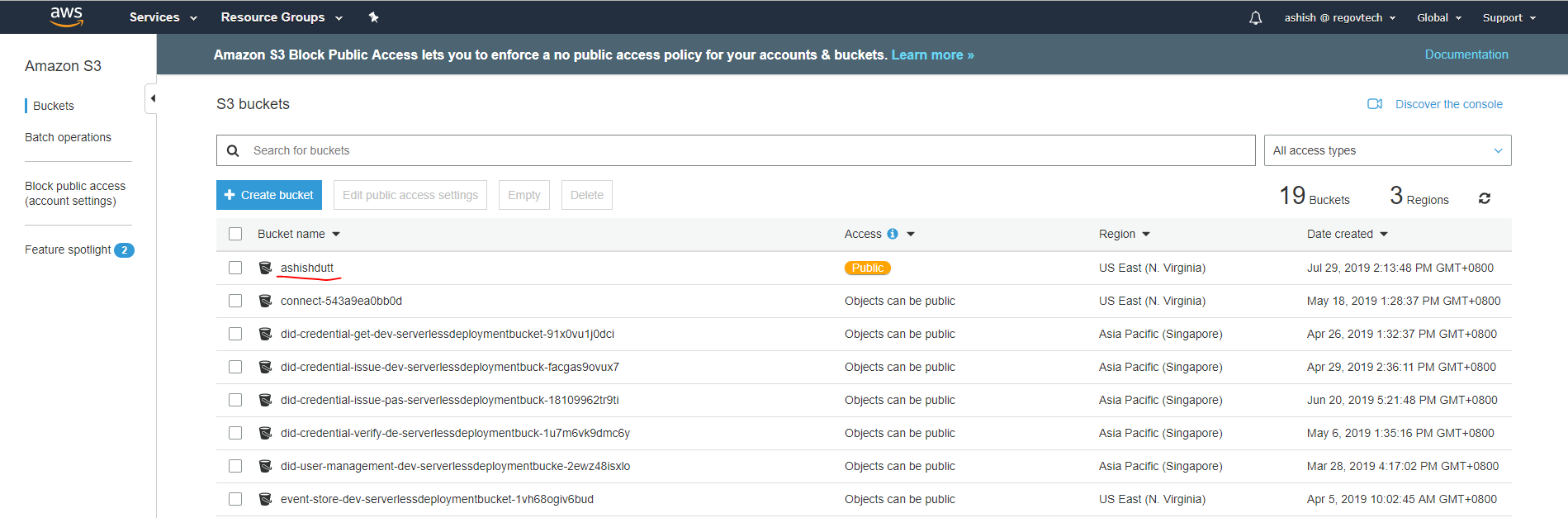
Step 2: Use the upload tab to upload external data into your bucket.
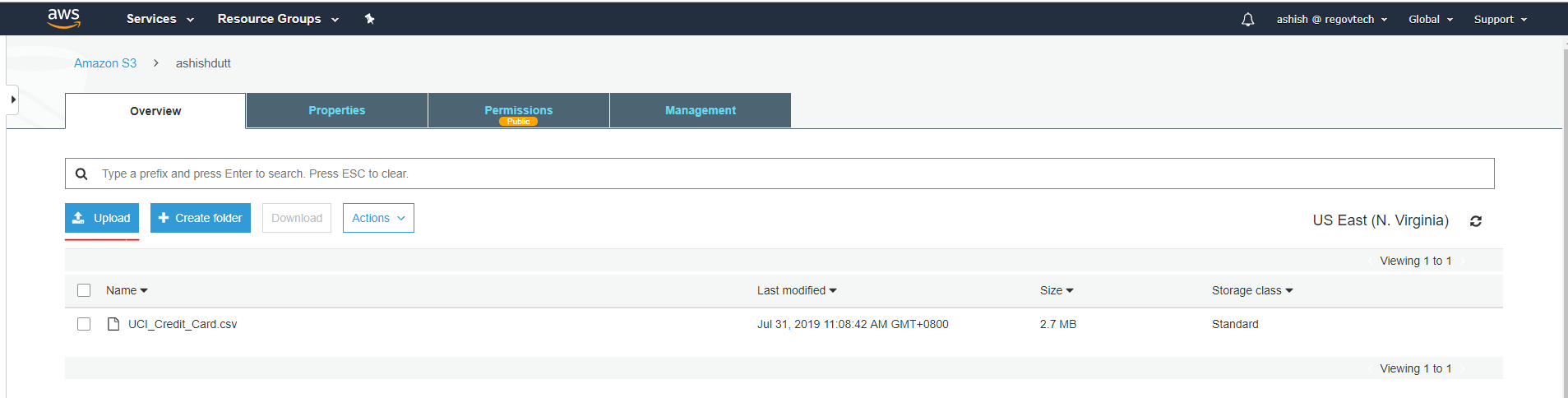
Step 3: Once the data is uploaded, click on it. In the Overview tab, at the bottom of the page you’ll see, Object Url. Copy this url and paste it in notepad.
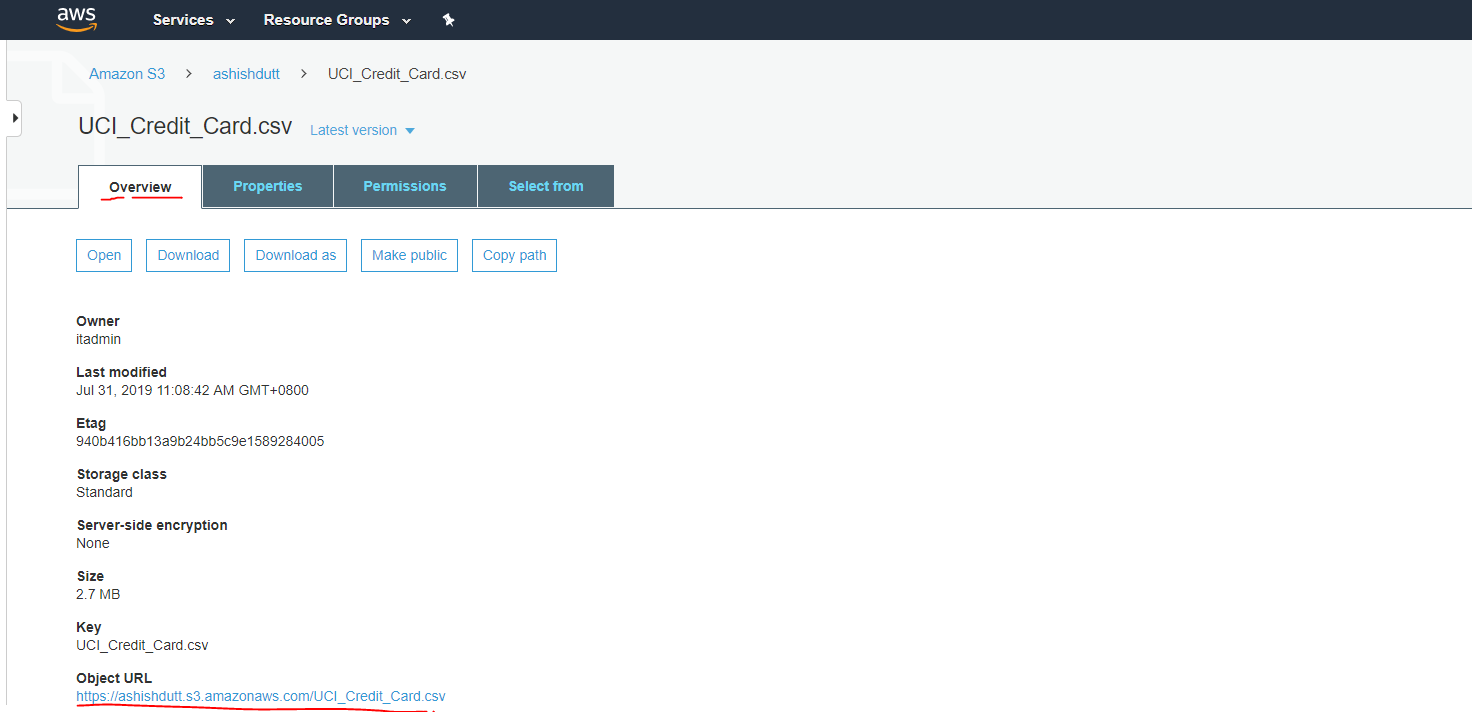
Step 4:
Now click on the Permissions tab.
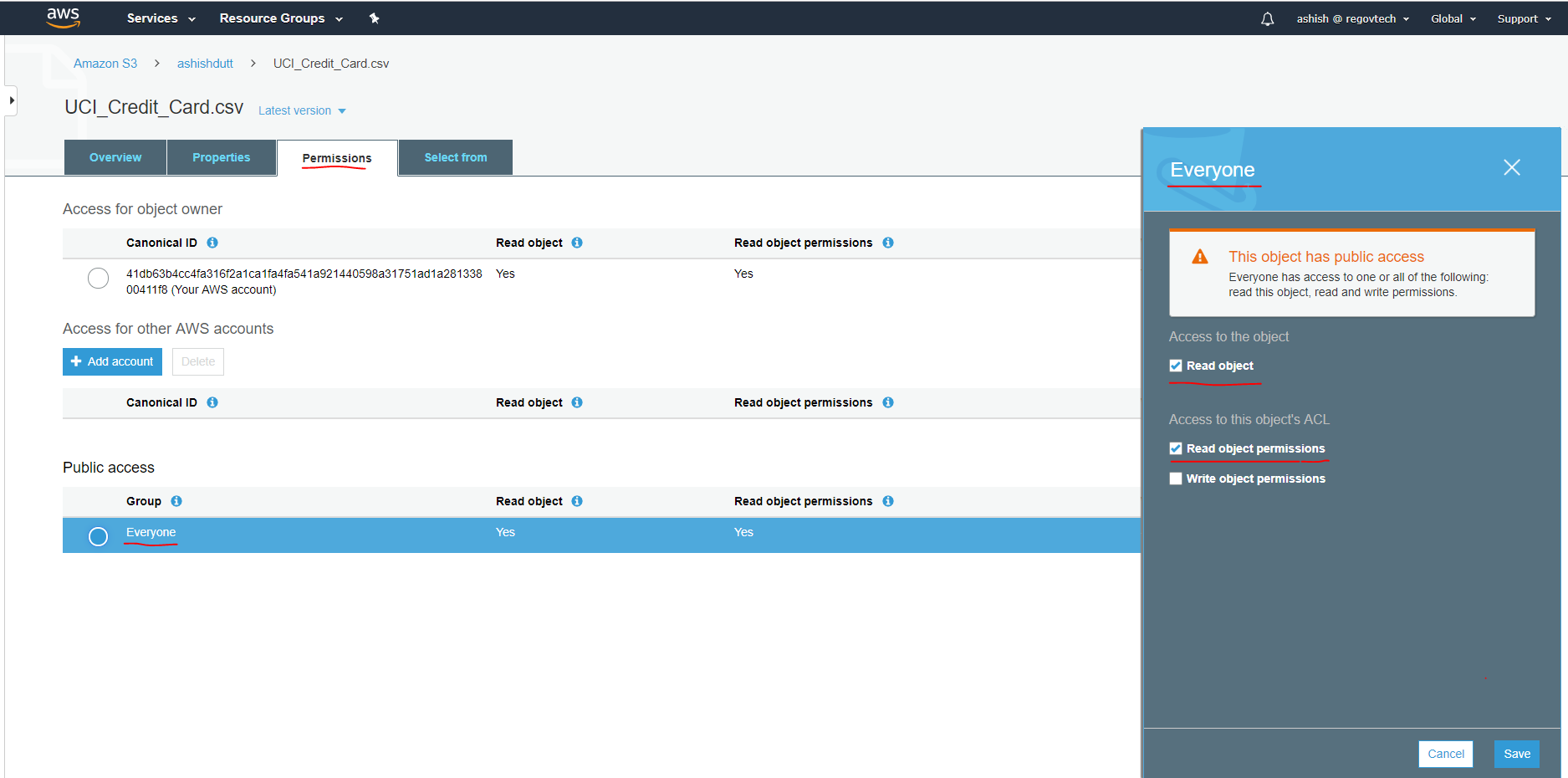
Under the section, Public access, click on the radio button Everyone. It will open up a window.
Put a checkmark on Read object permissions in Access to this objects ACL. This will give access to reading the data from the given object url.
Note: Do not give write object permission access. Also, if read access is not given then the data cannot be read by Sagemaker
AWS Sagemaker for consuming S3 data
Step 5
-
Open
AWS Sagemaker. -
From the Sagemaker dashboard, click on the button
create a notebook instance. I have already created one as shown below.
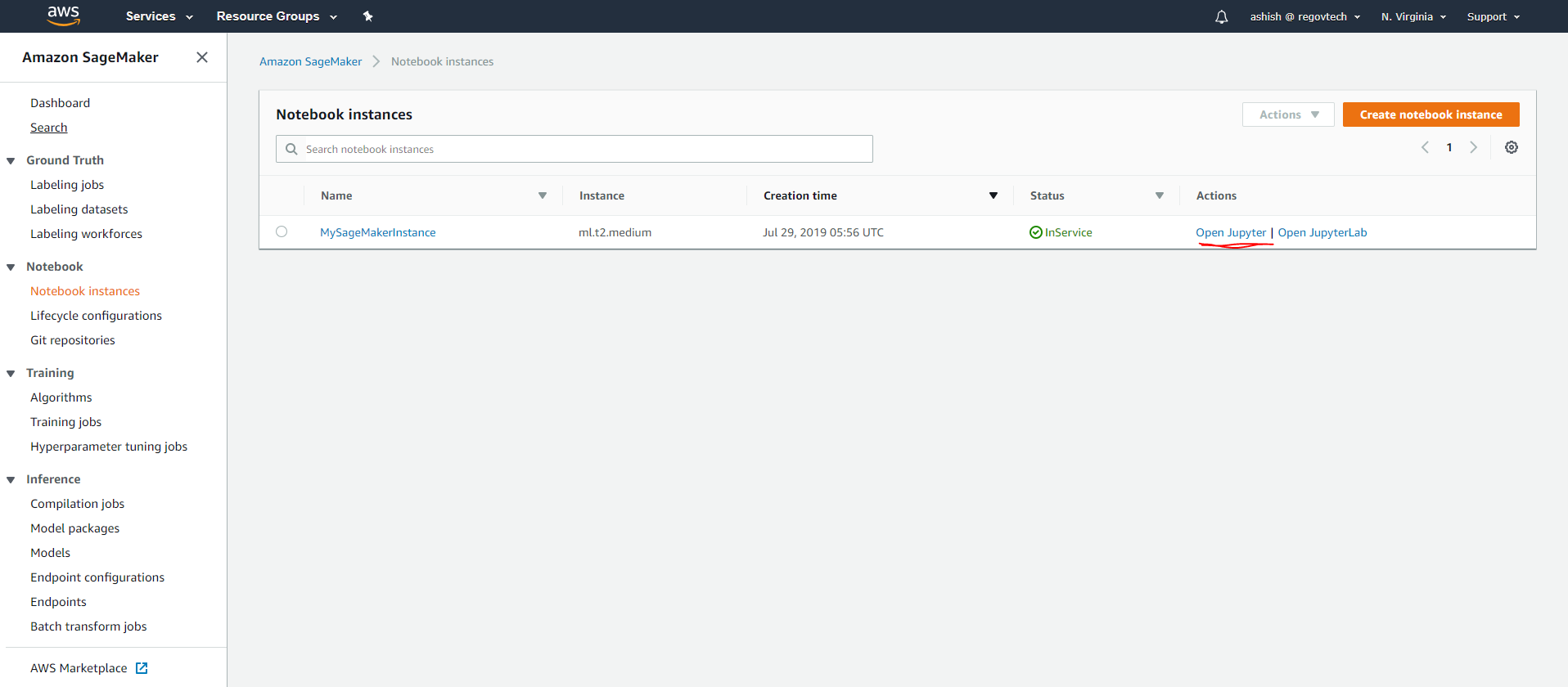
- click on
Open Jupytertab
Step 6
- In Sagemaker Jupyter notebook interface, click on the
Newtab (see screenshot) and choose the programming environment of your choice.
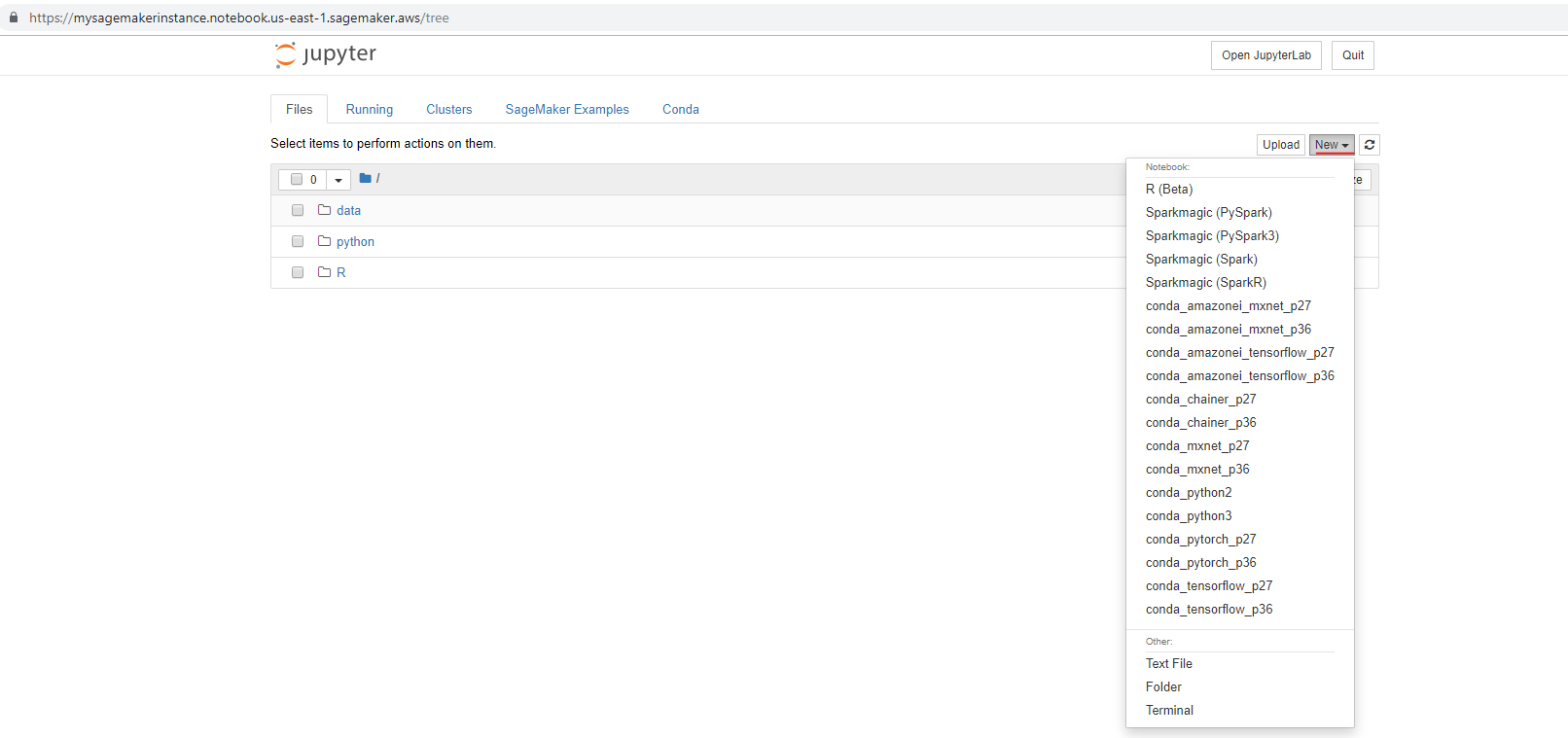
Step 7
- Read the data in the programming environment. I have chosen
Rin step 6.
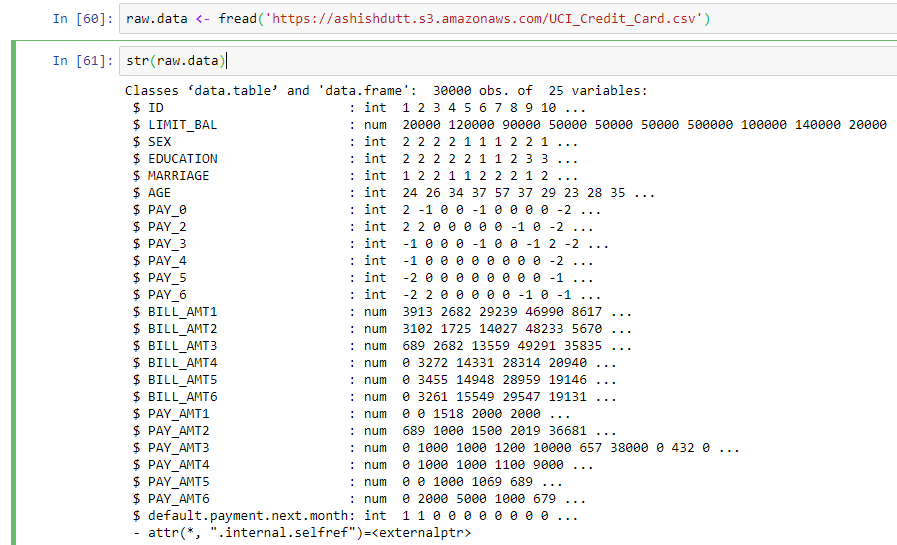
Accessing data in S3 bucket with python
There are two methods to access the data file;
- The Client method
- The Object URL method
See this IPython notebook for details.
AWS Data pipeline
To build an AWS Data pipeline, following steps need to be followed;
- Ensure the user has the required
IAM Roles. See this AWS documentation -
To use AWS Data Pipeline, you create a pipeline definition that specifies the business logic for your data processing. A typical pipeline definition consists of activities that define the work to perform, data nodes that define the location and type of input and output data, and a schedule that determines when the activities are performed.